

私有化部署方案的选型考虑包括模型参数、运行参数、算力硬件、配套生态及软件栈支持等。首先需要根据企业实际业务场景需求确定合适的模型参数和运行参数,再基于推理性能、并发需求和投入成本等多维度考虑确定算力硬件,同时也需要重点考量 AI 计算卡的配套生态和软件栈支持。
一、私有化部署大模型的一般流程
以昇腾 Atlas 800I A2 (8*64G)裸金属服务器为例,企业级部署 Deepseek-R1 模型的流程大致如下:
1.软件栈准备
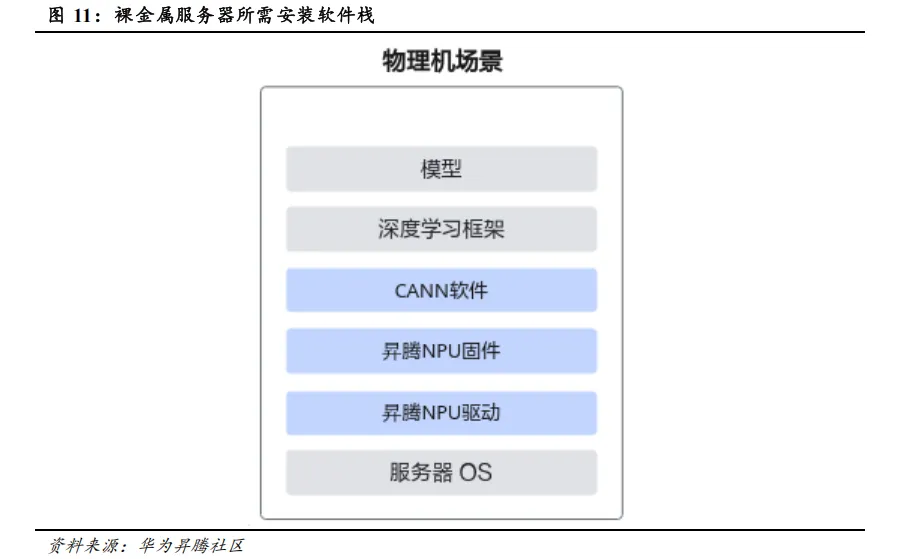
1)安装与配置服务器的底层操作系统,如 Ubuntu、Debian、openEuler 等。
2)安装昇腾 NPU(AI 计算卡)固件及驱动。
3)安装与配置昇腾提供的各类配套软件包,包括 Mindle(推理引擎)、CANN(异构计算架构)、MindSpore(AI 框架)等。

2.模型获取
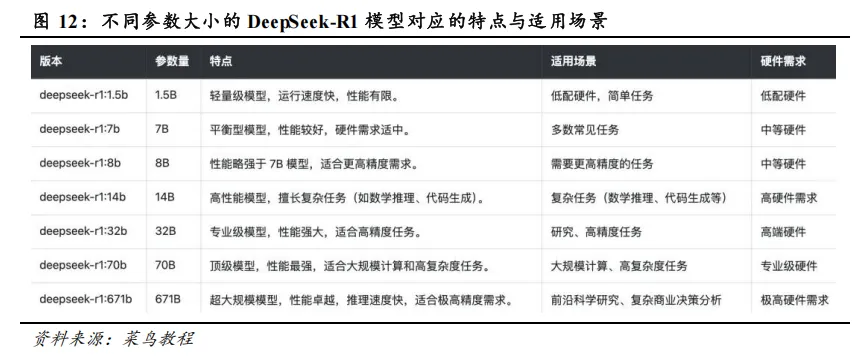
下载对应参数大小(671B 满血版或 70B 等蒸馏模型)的模型代码及权重,并转换为相应精度(FP8 或 FP16 等)。
3.推理服务部署
配置环境变量,启动推理服务容器并验证。
4.性能调优
调优推理引擎等软件栈的参数配置,从而达到最优推理效率。
5.安全与监控
进行网络安全设置、管理日志信息、配置监控看板等。
二、私有化部署方案的选型考虑一:模型参数和运行参数
企业级私有化部署 LLM 模型,首先需要考虑模型参数和运行参数。模型参数(满血版 or 蒸馏版)和运行参数(长下文长度、批次大小等)的大小决定了后续需要多少算力硬件,需要综合考虑企业实际业务场景需求。复杂决策场景,如金融研究分析、医疗影像诊断、法律文书分析等,需要较强的模型推理和上下文记忆能力,对于模型参数(70B以上)和上下文长度(32K 以上)的要求较高。一般复杂场景,如企业内部知识库、线上客服等,对于模型参数和运行参数的要求相对较低。
三、私有化部署方案的选型考虑二:算力硬件
AI 计算卡的性能直接决定了模型的推理性能和推理效率,从模型部署的最低算力硬件要求出发,显存容量是 AI 计算卡选型时所考虑的首要因素。AI 计算卡参数配置包括显存容量、显存带宽、计算能力、互联带宽等。其中,计算能力、显存带宽、互联带宽等直接影响模型推理的性能和效率,而显存容量则直接决定了模型能否正常部署。
1.显存容量
从满足模型部署的最低要求出发,首先需要考虑显存容量是否足够。不同的参数和计算精度的模型所需占用的显存容量不同,计算公式为模型参数×计算精度。以常见企业级生产部署环境为例:DeepSeek-R1-70B 模型,FP8 计算精度,序列长度(模型一次能处理的最大 token 数)8192,批次大小(Batch size,决定了模型一次处理的请求数量)16,一共需要约 70GB 的显存容量=模型参数:70B×模型精度:1 字节(FP8)。
此外还需要考虑一部分其他显存花销:
1)激活值缓存:模型运行时产生的中间计算结果,与模型参数和精度相关,计算公式为模型参数*模型精度*动态系数(0.1-0.5,取决于模型参数)。常见企业级生产部署环境下,一共需要约 17.50GB 的激活值缓存=模型参数:70B×模型精度:1 字节(FP8)×动态系数:0.25。
2)输出张量缓存:模型生成结果所需的临时存储空间,与批次大小、序列长度和词表大小相关,计算公式为批次大小×序列长度×词表大小×模型精度÷(1024³ )。常见企业级生产部署环境下,一共需要约 15.66GB 的输出张量缓存=批次大小: 16×序列长度: 8192×词表大小: 128256×模型精度: 1 字节(FP8)÷(1024³ )。
3)固定开销:AI 计算卡和模型初始化时的固定显存开销,包括软件栈缓存、算子编译缓存等,每个 AI 计算卡需要约 1.00GB。
综上,常见企业级生产部署环境下,一共需要约 104.16GB 的显存容量=模型占用:70.00GB+激活值缓存:17.50GB+输出张量缓存:15.66GB+固定开销:1.00GB。

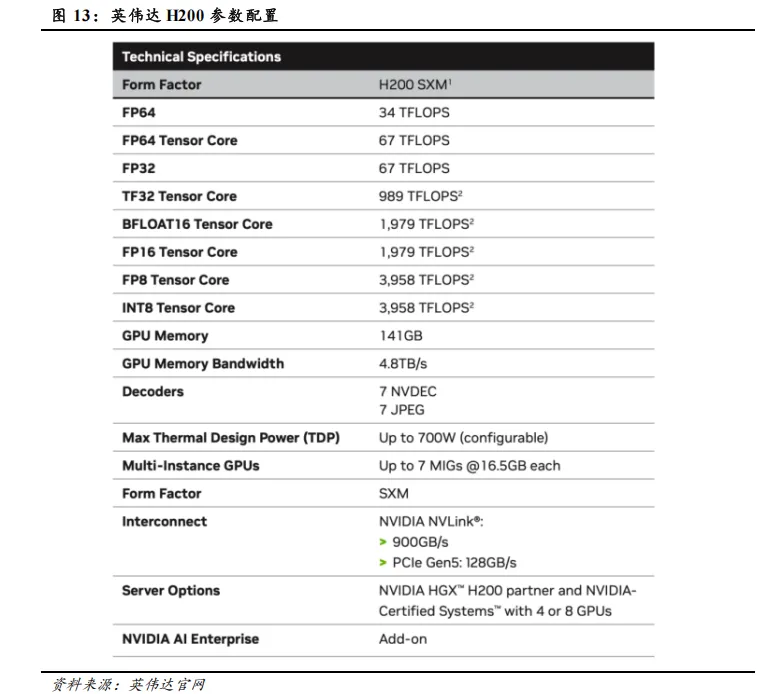
根据上述计算结果,1 张 NVIDIA H200(显存容量:141GB)或 2 张 NVIDIA H20(显存容量:96GB)或 2 张华为 Ascend 910B (显存容量:64GB)均可满足 70B 模型部署最低要求。但是若考虑到生产/开发/测试环境的隔离以及安全性与高可用性冗余等因素,实际业务场景下的模型部署最低要求可能会有所提高。
2.AI 算力大小、显存带宽、互联带宽等
在满足显存容量要求的前提下,AI 计算卡的计算能力、显存带宽、互联带宽等直接决定模型推理的性能和效率。
计算能力决定算力天花板。计算能力代表芯片在单位时间内完成矩阵乘法、卷积等核心运算的峰值能力,即每秒浮点运算次数的理论峰值。不同 AI 计算卡的计算架构与配套软件栈的优化情况存在差异,其实际计算效率会存在不同程度的折扣。
显存带宽决定数据传输效率。显存带宽代表显存与计算核心间的数据传输峰值速率,当模型参数或激活值的数据量(主要由 batch size 决定)超过带宽供给能力时,则模型推理性能与效率的瓶颈由显存带宽决定。
互联带宽则决定多卡互联的效率。在实际企业生产环境中,多为服务器内多卡互联的场景,互联带宽决定了服务器内多张 AI 计算卡之间的数据传输峰值速率。
硬件选型需要综合考虑推理性能、并发需求和投入成本。在企业级私有化部署的算力硬件选型中,除了需要满足显存容量的最低要求,还需要综合考虑模型推理的性能和效率(多少 token/s)以及并发需求量(多少并发量),具体包括 AI 计算卡的数量以及计算能力、显存带宽和互联带宽等参数,此外可能还需要考虑生产/开发/测试环境的隔离以及安全性与高可用性冗余等因素。根据拓维信息官方公众号,企业级部署DeepSeek-R1-70B 模型的推荐配置为 512G 显存容量,相当于 8 张华为 Ascend 910B (显存容量:64GB)的计算性能。

四、私有化部署方案的选型考虑三:配套生态及软件栈支持
AI 计算卡的配套生态及软件栈直接影响算力利用效率,同样很大程度上决定 AI 大模型的推理性能和效率。配套生态及软件栈支持主要包括算力硬件的固件及驱动和面向AI 大模型部署的各类配套软件包,其决定了算力使用效率、算力兼容性、模型部署及后续维护更新的难易程度,也是 AI 大模型部署解决方案选型时所考虑的重要一环。
AI 计算卡的固件及驱动决定了其底层计算效率,由芯片厂商提供与维护。以华为昇腾为例,固件的主要功能包括昇腾计算芯片自带的 OS、电源器件和功耗管理器件控制软件,分别用于后续加载到 AI 处理器的模型计算、处理器启动控制和功耗控制。驱动主要用于管理查询昇腾 AI 处理器,同时为上层 CANN 软件提供处理器控制、资源分配等接口。
配套软件包的作用在于帮助开发者优化基于 AI 计算卡训练和推理的效率和流程,更方便快捷地开发 AI 应用。以华为昇腾硬件平台为例,部署 Deepseek-R1 时可能需要的配套软件包有异构计算架构(CANN)、推理引擎(Mindle)、集合通信库(HCCL)、基础设施管理平台(DCS 套件)等。

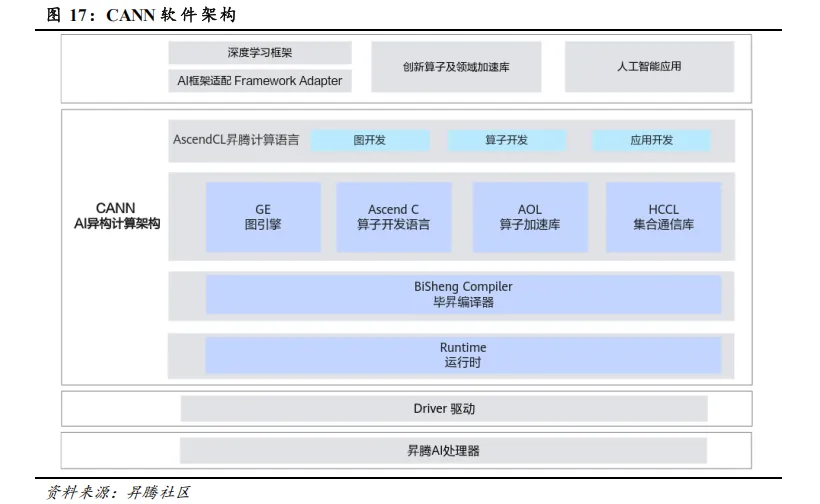
异构计算架构:整合 CPU、GPU、NPU 等不同处理器协同工作的计算模式,通过分工协作(如 GPU 加速并行计算、CPU 处理逻辑控制)来最大化硬件效能,适配 AI 大模型对海量算力的需求。典型代表包括英伟达 CUDA、华为昇腾 CANN。以 CANN(Compute Architecture for Neural Networks)为例,其是昇腾针对 AI 场景推出的异构计算架构,向上支持多种 AI 框架,包括 MindSpore、PyTorch、TensorFlow 等,向下服务 AI 处理器与编程,发挥承上启下的关键作用,是提升昇腾 AI 处理器计算效率的关键平台。
推理引擎:专为模型部署设计的优化工具,将训练模型转换为硬件高效执行的格式,集成量化压缩(FP32→INT8)、算子融合、内存复用等技术,显著降低推理延迟与资源消耗。典型代表包括vLLM、SG-Lang、英伟达NIM、华为 MindIE。以 MindIE(Mind Inference Engine,昇腾推理引擎)为例,其是华为昇腾针对 AI 全场景业务的推理加速套件。通过分层开放 AI 能力,支撑用户多样化的 AI 业务需求,使能百模千态,释放昇腾硬件设备算力。向上支持多种主流 AI 框架,向下对接不同类型昇腾 AI 处理器,提供多层次编程接口,帮助用户快速构建基于昇腾平台的推理业务。
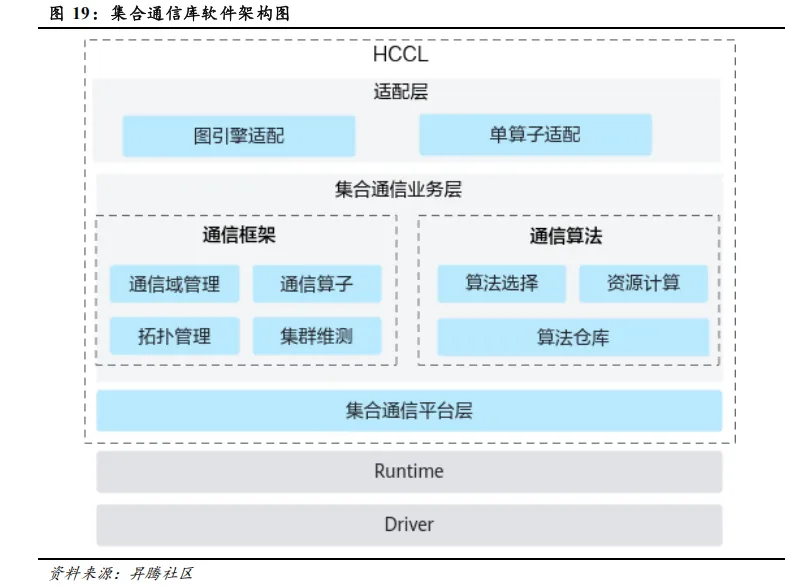
集合通信库:面向分布式训练的底层通信优化库,提供 AllReduce(梯度聚合)、Broadcast(参数同步)等高性能接口,利用 RDMA/NVLink 高速互联技术降低多节点通信延迟。典型代表如英伟达 NCCL、华为 HCCL。以 HCCL( Huawei Collective Communication Library)为例,其是基于昇腾 AI 计算卡的高性能集合通信库,提供单机多卡以及多机多卡间的数据并行、模型并行集合通信方案。
基础设施管理平台:集成了算力硬件虚拟化、异构算力管理、资源分配、弹性扩缩容、运维管理等一系列功能的 AI 大模型工具箱,支持 AI 大模型的全生命周期管理。市场参与者包括芯片厂商、云厂商、ICT 厂商等,典型代表包括英伟达 DGX SuperPOD、华为 DCS 套件、京东云 vGPU 算力池化平台、新华三灵犀平台。以华为 DCS 套件为例,其通过整合 ICT 硬件及进行系统级优化,提供统一运维管理、硬件资源虚拟化、异构算力资源管理和调度、灾备和安全等功能及服务。
